![]()
![]()
In cheapr, ‘cheap’ means fast and memory-efficient, and that’s exactly the philosophy that cheapr aims to follow.
You can install cheapr like so:
install.packages("cheapr")or you can install the development version of cheapr:
remotes::install_github("NicChr/cheapr")Some common operations that cheapr can do much faster and more efficiently include:
Counting, finding, removing and replacing NA and
scalar values
Creating factors
Creating multiple sequences in a vectorised way
Sub-setting vectors and data frames efficiently
Safe, flexible and fast greatest common divisor and lowest common multiple
Lags/leads
Lightweight integer64 support
In-memory Math (no copies, vectors updated by reference)
Summary statistics of data frame variables
Binning of continuous data
Let’s first load the required packages
library(cheapr)
library(bench)num_na() is a useful function to efficiently return the
number of NA values and can be used in a variety of
problems.
Almost all the NA handling functions in cheapr can make
use of multiple cores on your machine through openMP.
x <- rep(NA, 10^6)
# 1 core by default
mark(num_na(x), sum(is.na(x)))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 num_na(x) 996µs 1.03ms 972. 2.41KB 0
#> 2 sum(is.na(x)) 776µs 1.77ms 577. 3.81MB 48.3
# 4 cores
options(cheapr.cores = 4)
mark(num_na(x), sum(is.na(x)))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 num_na(x) 261µs 367.55µs 2539. 0B 0
#> 2 sum(is.na(x)) 784µs 1.75ms 576. 3.81MB 46.7
options(cheapr.cores = 1)m <- matrix(x, ncol = 10^3)
# Number of NA values by row
mark(row_na_counts(m),
rowSums(is.na(m)))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 row_na_counts(m) 1.74ms 1.83ms 539. 9.12KB 0
#> 2 rowSums(is.na(m)) 2.58ms 3.64ms 278. 3.82MB 26.4
# Number of NA values by col
mark(col_na_counts(m),
colSums(is.na(m)))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 col_na_counts(m) 2.29ms 2.4ms 413. 9.12KB 0
#> 2 colSums(is.na(m)) 1.78ms 2.8ms 366. 3.82MB 34.4is_na is a multi-threaded alternative to
is.na
x <- rnorm(10^6)
x[sample.int(10^6, 10^5)] <- NA
mark(is.na(x), is_na(x))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 is.na(x) 733µs 1.83ms 546. 3.81MB 81.8
#> 2 is_na(x) 1.3ms 2.51ms 413. 3.82MB 40.5
### posixlt method is much faster
hours <- as.POSIXlt(seq.int(0, length.out = 10^6, by = 3600),
tz = "UTC")
hours[sample.int(10^6, 10^5)] <- NA
mark(is.na(hours), is_na(hours))
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 is.na(hours) 1.21s 1.21s 0.826 61MB 0.826
#> 2 is_na(hours) 13.05ms 15.27ms 63.9 13.9MB 7.74It differs in 2 regards:
NA when either that
element is an NA value or it is a list containing only
NA values.is_na returns a logical vector where
TRUE defines an empty row of only NA
values.# List example
is.na(list(NA, list(NA, NA), 10))
#> [1] TRUE FALSE FALSE
is_na(list(NA, list(NA, NA), 10))
#> [1] TRUE TRUE FALSE
# Data frame example
df <- data.frame(x = c(1, NA, 3),
y = c(NA, NA, NA))
df
#> x y
#> 1 1 NA
#> 2 NA NA
#> 3 3 NA
is_na(df)
#> [1] FALSE TRUE FALSE
is_na(df)
#> [1] FALSE TRUE FALSE
# The below identity should hold
identical(is_na(df), row_na_counts(df) == ncol(df))
#> [1] TRUEis_na and all the NA handling functions
fall back on calling is.na() if no suitable method is
found. This means that custom objects like vctrs rcrds and more are
supported.
overviewInspired by the excellent skimr package, overview() is a
cheaper alternative designed for larger data.
set.seed(42)
df <- data.frame(
x = sample.int(100, 10^7, TRUE),
y = factor_(sample(LETTERS, 10^7, TRUE)),
z = rnorm(10^7)
)
overview(df)
#> obs: 10000000
#> cols: 3
#>
#> ----- Numeric -----
#> col class n_missng p_complt n_unique mean p0 p25 p50 p75
#> 1 x integr 0 1 100 50.51 1 26 51 76
#> 2 z numerc 0 1 10000000 -0.000089 -5.16 -0.68 -0.00014 0.67
#> p100 iqr sd hist
#> 1 100 50 28.86 ▇▇▇▇▇
#> 2 5.26 1.35 1 ▁▂▇▂▁
#>
#> ----- Categorical -----
#> col class n_missng p_complt n_unique n_levels min max
#> 1 y factor 0 1 26 26 A Z
mark(overview(df, hist = FALSE))
#> # A tibble: 1 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 overview(df, hist = FALSE) 1.31s 1.31s 0.764 2.09KB 0ssetsset(iris, 1:5)
#> Sepal.Length Sepal.Width Petal.Length Petal.Width Species
#> 1 5.1 3.5 1.4 0.2 setosa
#> 2 4.9 3.0 1.4 0.2 setosa
#> 3 4.7 3.2 1.3 0.2 setosa
#> 4 4.6 3.1 1.5 0.2 setosa
#> 5 5.0 3.6 1.4 0.2 setosa
sset(iris, 1:5, j = "Species")
#> Species
#> 1 setosa
#> 2 setosa
#> 3 setosa
#> 4 setosa
#> 5 setosa
# sset always returns a data frame when input is a data frame
sset(iris, 1, 1) # data frame
#> Sepal.Length
#> 1 5.1
iris[1, 1] # not a data frame
#> [1] 5.1
x <- sample.int(10^6, 10^4, TRUE)
y <- sample.int(10^6, 10^4, TRUE)
mark(sset(x, x %in_% y), sset(x, x %in% y), x[x %in% y])
#> # A tibble: 3 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 sset(x, x %in_% y) 78.3µs 116µs 8915. 83.2KB 6.52
#> 2 sset(x, x %in% y) 159.6µs 242µs 4157. 285.4KB 8.77
#> 3 x[x %in% y] 132µs 218µs 4561. 324.5KB 13.7sset uses an internal range-based subset when
i is an ALTREP integer sequence of the form m:n.
mark(sset(df, 0:10^5), df[0:10^5, , drop = FALSE])
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 sset(df, 0:10^5) 138.5µs 580.7µs 1741. 1.53MB 23.7
#> 2 df[0:10^5, , drop = FALSE] 6.08ms 7.11ms 139. 4.83MB 6.51It also accepts negative indexes
mark(sset(df, -10^4:0),
df[-10^4:0, , drop = FALSE],
check = FALSE) # The only difference is the row names
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 sset(df, -10^4:0) 64.68ms 118.01ms 7.94 152MB 4.77
#> 2 df[-10^4:0, , drop = FALSE] 1.03s 1.03s 0.975 776MB 1.95The biggest difference between sset and [
is the way logical vectors are handled. The two main differences when
i is a logical vector are:
NA values are ignored, only the locations of
TRUE values are used.i must be the same length as x and is not
recycled.# Examples with NAs
x <- c(1, 5, NA, NA, -5)
x[x > 0]
#> [1] 1 5 NA NA
sset(x, x > 0)
#> [1] 1 5
# Example with length(i) < length(x)
sset(x, TRUE)
#> Error in check_length(i, length(x)): i must have length 5
# This is equivalent
x[TRUE]
#> [1] 1 5 NA NA -5
# to..
sset(x)
#> [1] 1 5 NA NA -5lag_()set.seed(37)
lag_(1:10, 3) # Lag(3)
#> [1] NA NA NA 1 2 3 4 5 6 7
lag_(1:10, -3) # Lead(3)
#> [1] 4 5 6 7 8 9 10 NA NA NA
# Using an example from data.table
library(data.table)
dt <- data.table(year=2010:2014, v1=runif(5), v2=1:5, v3=letters[1:5])
# Similar to data.table::shift()
lag_(dt, 1) # Lag
#> year v1 v2 v3
#> <int> <num> <int> <char>
#> 1: NA NA NA <NA>
#> 2: 2010 0.54964085 1 a
#> 3: 2011 0.07883715 2 b
#> 4: 2012 0.64879698 3 c
#> 5: 2013 0.49685336 4 d
lag_(dt, -1) # Lead
#> year v1 v2 v3
#> <int> <num> <int> <char>
#> 1: 2011 0.07883715 2 b
#> 2: 2012 0.64879698 3 c
#> 3: 2013 0.49685336 4 d
#> 4: 2014 0.71878731 5 e
#> 5: NA NA NA <NA>With lag_ we can update variables by reference,
including entire data frames
# At the moment, shift() cannot do this
lag_(dt, set = TRUE)
#> year v1 v2 v3
#> <int> <num> <int> <char>
#> 1: NA NA NA <NA>
#> 2: 2010 0.54964085 1 a
#> 3: 2011 0.07883715 2 b
#> 4: 2012 0.64879698 3 c
#> 5: 2013 0.49685336 4 d
dt # Was updated by reference
#> year v1 v2 v3
#> <int> <num> <int> <char>
#> 1: NA NA NA <NA>
#> 2: 2010 0.54964085 1 a
#> 3: 2011 0.07883715 2 b
#> 4: 2012 0.64879698 3 c
#> 5: 2013 0.49685336 4 dlag2_ is a more generalised variant that supports
vectors of lags, custom ordering and run lengths.
lag2_(dt, order = 5:1) # Reverse order lag (same as lead)
#> year v1 v2 v3
#> <int> <num> <int> <char>
#> 1: 2010 0.54964085 1 a
#> 2: 2011 0.07883715 2 b
#> 3: 2012 0.64879698 3 c
#> 4: 2013 0.49685336 4 d
#> 5: NA NA NA <NA>
lag2_(dt, -1) # Same as above
#> year v1 v2 v3
#> <int> <num> <int> <char>
#> 1: 2010 0.54964085 1 a
#> 2: 2011 0.07883715 2 b
#> 3: 2012 0.64879698 3 c
#> 4: 2013 0.49685336 4 d
#> 5: NA NA NA <NA>
lag2_(dt, c(1, -1)) # Alternating lead/lag
#> year v1 v2 v3
#> <int> <num> <int> <char>
#> 1: NA NA NA <NA>
#> 2: 2011 0.07883715 2 b
#> 3: 2010 0.54964085 1 a
#> 4: 2013 0.49685336 4 d
#> 5: 2012 0.64879698 3 c
lag2_(dt, c(-1, 0, 0, 0, 0)) # Lead e.g. only first row
#> year v1 v2 v3
#> <int> <num> <int> <char>
#> 1: 2010 0.54964085 1 a
#> 2: 2010 0.54964085 1 a
#> 3: 2011 0.07883715 2 b
#> 4: 2012 0.64879698 3 c
#> 5: 2013 0.49685336 4 dgcd2(5, 25)
#> [1] 5
scm2(5, 6)
#> [1] 30
gcd(seq(5, 25, by = 5))
#> [1] 5
scm(seq(5, 25, by = 5))
#> [1] 300
x <- seq(1L, 1000000L, 1L)
mark(gcd(x))
#> # A tibble: 1 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 gcd(x) 1.3µs 1.5µs 647509. 0B 0
x <- seq(0, 10^6, 0.5)
mark(gcd(x))
#> # A tibble: 1 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 gcd(x) 50.8ms 51ms 19.6 0B 0As an example, to create 3 sequences with different increments,
the usual approach might be to use lapply to loop through the increment
values together with seq()
# Base R
increments <- c(1, 0.5, 0.1)
start <- 1
end <- 5
unlist(lapply(increments, \(x) seq(start, end, x)))
#> [1] 1.0 2.0 3.0 4.0 5.0 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.0 1.1 1.2 1.3 1.4
#> [20] 1.5 1.6 1.7 1.8 1.9 2.0 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3.0 3.1 3.2 3.3
#> [39] 3.4 3.5 3.6 3.7 3.8 3.9 4.0 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 5.0In cheapr you can use seq_() which accepts vector
arguments.
seq_(start, end, increments)
#> [1] 1.0 2.0 3.0 4.0 5.0 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.0 1.1 1.2 1.3 1.4
#> [20] 1.5 1.6 1.7 1.8 1.9 2.0 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3.0 3.1 3.2 3.3
#> [39] 3.4 3.5 3.6 3.7 3.8 3.9 4.0 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 5.0Use add_id = TRUE to label the individual sequences.
seq_(start, end, increments, add_id = TRUE)
#> 1 1 1 1 1 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3
#> 1.0 2.0 3.0 4.0 5.0 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.0 1.1 1.2 1.3 1.4 1.5
#> 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
#> 1.6 1.7 1.8 1.9 2.0 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3.0 3.1 3.2 3.3 3.4 3.5
#> 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
#> 3.6 3.7 3.8 3.9 4.0 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 5.0If you know the sizes of your sequences beforehand, use
sequence_()
seq_sizes <- c(3, 5, 10)
sequence_(seq_sizes, from = 0, by = 1/3, add_id = TRUE) |>
enframe_()
#> # A tibble: 18 × 2
#> name value
#> <chr> <dbl>
#> 1 1 0
#> 2 1 0.333
#> 3 1 0.667
#> 4 2 0
#> 5 2 0.333
#> 6 2 0.667
#> 7 2 1
#> 8 2 1.33
#> 9 3 0
#> 10 3 0.333
#> 11 3 0.667
#> 12 3 1
#> 13 3 1.33
#> 14 3 1.67
#> 15 3 2
#> 16 3 2.33
#> 17 3 2.67
#> 18 3 3You can also calculate the sequence sizes using
seq_size()
seq_size(start, end, increments)
#> [1] 5 9 41x <- rep(TRUE, 10^6)
mark(cheapr_which = which_(x),
base_which = which(x))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_which 3.6ms 4.16ms 189. 3.81MB 0
#> 2 base_which 658.4µs 7.45ms 166. 7.63MB 2.07
x <- rep(FALSE, 10^6)
mark(cheapr_which = which_(x),
base_which = which(x))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_which 766µs 792µs 1255. 0B 0
#> 2 base_which 455µs 468µs 2035. 3.81MB 13.5
x <- c(rep(TRUE, 5e05), rep(FALSE, 1e06))
mark(cheapr_which = which_(x),
base_which = which(x))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_which 2.1ms 2.75ms 354. 1.91MB 2.07
#> 2 base_which 780.3µs 1.96ms 423. 7.63MB 4.29
x <- c(rep(FALSE, 5e05), rep(TRUE, 1e06))
mark(cheapr_which = which_(x),
base_which = which(x))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_which 3.53ms 5.24ms 162. 3.81MB 2.07
#> 2 base_which 927.7µs 3.86ms 168. 9.54MB 2.05
x <- sample(c(TRUE, FALSE), 10^6, TRUE)
x[sample.int(10^6, 10^4)] <- NA
mark(cheapr_which = which_(x),
base_which = which(x))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_which 2.35ms 4.79ms 228. 1.89MB 2.09
#> 2 base_which 3.98ms 4.25ms 178. 5.7MB 0x <- sample(seq(-10^3, 10^3, 0.01))
y <- do.call(paste0, expand.grid(letters, letters, letters, letters))
mark(cheapr_factor = factor_(x),
base_factor = factor(x))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_factor 9.46ms 9.93ms 100. 4.59MB 0
#> 2 base_factor 583.81ms 583.81ms 1.71 27.84MB 0
mark(cheapr_factor = factor_(x, order = FALSE),
base_factor = factor(x, levels = unique(x)))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_factor 5.07ms 7.39ms 142. 1.53MB 0
#> 2 base_factor 896.43ms 896.43ms 1.12 22.79MB 0
mark(cheapr_factor = factor_(y),
base_factor = factor(y))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_factor 210.4ms 212.18ms 4.70 5.23MB 0
#> 2 base_factor 2.87s 2.87s 0.349 54.35MB 0
mark(cheapr_factor = factor_(y, order = FALSE),
base_factor = factor(y, levels = unique(y)))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_factor 4.78ms 7.64ms 124. 3.49MB 2.26
#> 2 base_factor 53.78ms 62.29ms 15.3 39.89MB 0x <- sample.int(10^6, 10^5, TRUE)
y <- sample.int(10^6, 10^5, TRUE)
mark(cheapr_intersect = intersect_(x, y, dups = FALSE),
base_intersect = intersect(x, y))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_intersect 2.82ms 4ms 234. 1.18MB 0
#> 2 base_intersect 4.89ms 5.94ms 130. 5.16MB 2.20
mark(cheapr_setdiff = setdiff_(x, y, dups = FALSE),
base_setdiff = setdiff(x, y))
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_setdiff 2.96ms 3.22ms 307. 1.76MB 0
#> 2 base_setdiff 5.97ms 10.81ms 87.0 5.71MB 0%in_% and %!in_%mark(cheapr = x %in_% y,
base = x %in% y)
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr 1.72ms 2.11ms 445. 781.34KB 2.19
#> 2 base 2.83ms 3.06ms 304. 2.53MB 0
mark(cheapr = x %!in_% y,
base = !x %in% y)
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr 2.21ms 2.51ms 376. 787.84KB 0
#> 2 base 2.6ms 3.61ms 210. 2.91MB 2.21as_discreteas_discrete is a cheaper alternative to
cut
x <- rnorm(10^7)
b <- seq(0, max(x), 0.2)
mark(cheapr_cut = as_discrete(x, b, left = FALSE),
base_cut = cut(x, b))
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 cheapr_cut 225ms 248ms 4.11 38.2MB 0
#> 2 base_cut 516ms 516ms 1.94 267.1MB 1.94cheapr_if_elseA cheap alternative to ifelse
mark(
cheapr_if_else(x >= 0, "pos", "neg"),
ifelse(x >= 0, "pos", "neg"),
data.table::fifelse(x >= 0, "pos", "neg")
)
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.
#> # A tibble: 3 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 "cheapr_if_else(x >= 0, \"pos\… 127ms 130.95ms 7.43 114MB 1.86
#> 2 "ifelse(x >= 0, \"pos\", \"neg… 1.82s 1.82s 0.550 534MB 1.10
#> 3 "data.table::fifelse(x >= 0, \… 114.59ms 128.77ms 7.79 114MB 1.95casecheapr’s version of a case-when statement, with mostly the same
arguments as dplyr::case_when but similar efficiency as
data.table::fcase
mark(case(
x >= 0 ~ "pos",
x < 0 ~ "neg",
.default = "Unknown"
),
data.table::fcase(
x >= 0, "pos",
x < 0, "neg",
rep_len(TRUE, length(x)), "Unknown"
))
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch> <bch:> <dbl> <bch:byt> <dbl>
#> 1 "case(x >= 0 ~ \"pos\", x < 0 ~ \"n… 416ms 433ms 2.31 286MB 2.31
#> 2 "data.table::fcase(x >= 0, \"pos\",… 278ms 309ms 3.24 267MB 4.86val_match is an even cheaper special variant of
case when all LHS expressions are length-1 vectors, i.e
scalars
x <- round(rnorm(10^7))
mark(
val_match(x, 1 ~ Inf, 2 ~ -Inf, .default = NaN),
case(x == 1 ~ Inf,
x == 2 ~ -Inf,
.default = NaN),
data.table::fcase(x == 1, Inf,
x == 2, -Inf,
rep_len(TRUE, length(x)), NaN)
)
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.
#> # A tibble: 3 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch> <bch:> <dbl> <bch:byt> <dbl>
#> 1 val_match(x, 1 ~ Inf, 2 ~ -Inf, .de… 135ms 192ms 5.75 87.9MB 1.92
#> 2 case(x == 1 ~ Inf, x == 2 ~ -Inf, .… 450ms 464ms 2.16 276.2MB 1.08
#> 3 data.table::fcase(x == 1, Inf, x ==… 328ms 330ms 3.03 305.2MB 3.03get_breaks is a very fast function for generating pretty
equal-width breaks It is similar to base::pretty though
somewhat less flexible with simpler arguments.
x <- with_local_seed(rnorm(10^5), 112)
# approximately 10 breaks
get_breaks(x, 10)
#> [1] -6 -4 -2 0 2 4 6
pretty(x, 10)
#> [1] -6 -5 -4 -3 -2 -1 0 1 2 3 4 5
mark(
get_breaks(x, 20),
pretty(x, 20),
check = FALSE
)
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 get_breaks(x, 20) 101µs 103.5µs 9225. 0B 0
#> 2 pretty(x, 20) 392µs 2.19ms 485. 1.91MB 4.19
# Not pretty but equal width breaks
get_breaks(x, 5, pretty = FALSE)
#> [1] -5.0135893 -3.2004889 -1.3873886 0.4257118 2.2388121 4.0519125
diff(get_breaks(x, 5, pretty = FALSE)) # Widths
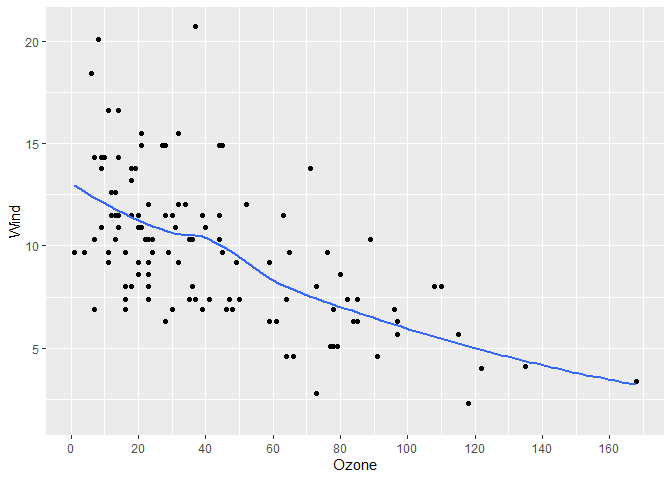
#> [1] 1.8131 1.8131 1.8131 1.8131 1.8131It can accept both data and a length-two vector representing a range, meaning it can easily be used in ggplot2 and base R plots
library(ggplot2)
gg <- airquality |>
ggplot(aes(x = Ozone, y = Wind)) +
geom_point() +
geom_smooth(se = FALSE)
# Add our breaks
gg +
scale_x_continuous(breaks = get_breaks)
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'
#> Warning: Removed 37 rows containing non-finite outside the scale range
#> (`stat_smooth()`).
#> Warning: Removed 37 rows containing missing values or values outside the scale range
#> (`geom_point()`).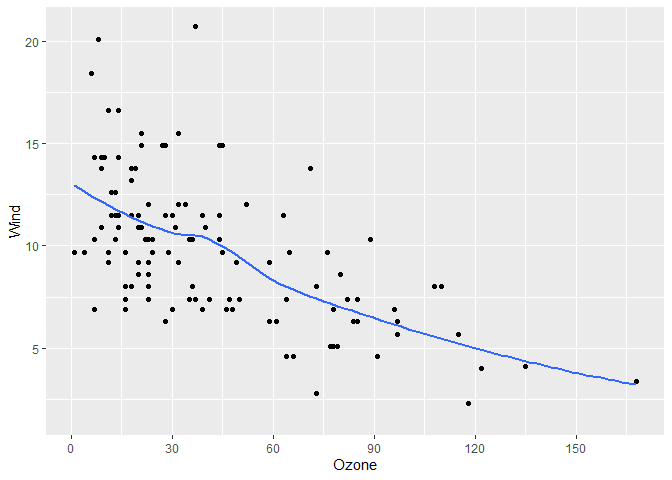
# More breaks
# get_breaks accepts a range too
gg +
scale_x_continuous(breaks = \(x) get_breaks(range(x), 20))
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'
#> Warning: Removed 37 rows containing non-finite outside the scale range
#> (`stat_smooth()`).
#> Removed 37 rows containing missing values or values outside the scale range
#> (`geom_point()`).